- Smart Keyboard PRO + BackupAuto Teks>> http://adf.ly/ItIcS
- 1Mobile Market (MarketgantinyaPlaystore) >> http://adf.ly/QCBvl
- 2x Battery Saver >> http://adf.ly/ItJsY
- 4Shared PRO >> http://adf.ly/IzREZ
- Adobe Flash Player >> http://adf.ly/QCBjv
- Adobe Photoshop Touch >> http://adf.ly/ItKAq
- Advanced Taks manager Pro >> http://adf.ly/ItKMd
- Andro IRC >> http://adf.ly/ItKee
- Anti Mosquito ( Apppengusir nyamuk) >> http://adf.ly/QCBbV
- Anti Theft Alarm PRO ( Appanti maling) >> http://adf.ly/ItKsx
- Antutu Benchmark >> http://adf.ly/ItKys
- Antutu Power saver >> http://adf.ly/IzD1I
- App2SD PRO >> http://adf.ly/ItL4r
- Applanet (Marketgantinyaplaystore) >> http://adf.ly/QCB4z
- ASTRO file manager PRO >> http://adf.ly/ItLzc
- AVAST >> http://adf.ly/ItMFd
- Barcode Scanner PLUS >> http://adf.ly/ItMZ1
- Bear Rocket (LOCKSCREEN) >> http://adf.ly/ItMfw
- BLACKMART ALPHA (semua App ygdi PLAYSTORE akan GRATIS semuadisinigan) >>http://adf.ly/JgYcV
- Bluetooth File Transfer (buatygsusahKirimFile lewatbluetooth for HH belum ROOT) >>http://adf.ly/ItMsE
- Beautiful widget >> http://adf.ly/ItN5o
- Busy Box PRO >> http://adf.ly/QCBzE
- CalcBuddy (AppKalkulatorfiturlengkap) >> http://adf.ly/ItNSI
- Camera 360 >>http://adf.ly/IzCMh
- Camera HDRC >> http://adf.ly/ItNYy
- Catfis (App Messengerpengganti BBM dengan PIN) >> http://adf.ly/ItNiI
- Google Chrome >> http://adf.ly/ItNtt
- DR. WEB Anti VIRUSLifeLicensi >> http://adf.ly/JgZ1l
- Desktop Visualizer >> http://adf.ly/ItO1X
- Directory Bind (INSTAL DATAGAME di EXT_CARD) >> http://adf.ly/ItOIx
- DO'A Harian ( Buat yangsukalupabaca DO'A :D) >> http://adf.ly/ItOfM
- Droid scan PRO >> http://adf.ly/ItOzy
- DX TOOLBOX >> http://adf.ly/ItP6a
- Evernote >> http://adf.ly/ItPCg
- FONT Changer (buatganti Font) >> http://adf.ly/ItPJt
- FPse (Emulator PS for Android)>> http://adf.ly/ItPUC
- FPse Need Patch >> http://adf.ly/ItPep
- Funny Teks Creator (BuatketikhurufunicodeBB style) >> http://adf.ly/ItPoj
- GAME Booster ( Mantapbuat paraGAMERS) >> http://adf.ly/ItQ1t
- GAME Keyboard (Buatketik Cheatwaktu GAME Play) >> http://adf.ly/ItQDJ
- Genius Scan >> http://adf.ly/ItQPi
- GHOSTCAM (SepertinamanyaKamerahantuhihihiiii)>> http://adf.ly/IzDwD
- GO LAUNCHER >> http://adf.ly/ItQZT
- Google Play Store >> http://adf.ly/ItQhO
- Green POWER PRO (PenghematBatterai.Go GREEN Gan :D) >> http://adf.ly/ItQml
- HEX Editor >> http://adf.ly/IzEaQ
- HIDE it PRO Alias Audio Manager (Appbuatmenyembunyikan file paling ampuh. Waktu di instalnamanyaberubahjadi
AUDIO MANAGER jadi gag bakalmencurigakan, dilengkapidengan pin n password)
>> http://adf.ly/ItQxZ - INDO TV ( Nonton TV Onlinegan) >> http://adf.ly/ItRWO
- I QUR'AN PRO (App Alqur'an) >> http://adf.ly/ItRiX
- Kalibrasi Touch (buat yangbermasalahdengan touchscreen ) >> http://adf.ly/ItS5A
- Kamusbesarbahasaindonesia >> http://adf.ly/ItSEW
- KAMUSKU (inggris-indonesiaindonesia-inggris)>> http://adf.ly/ItSKq
- Kingsoft Office International (AppOffice) >> http://adf.ly/ItSUB
- Launcher Windows Phone 8 >> http://adf.ly/ItSfm
- Light Flow LED control (buataturLED notification) >> http://adf.ly/ItSnQ
- Lighning Launcher >> http://adf.ly/IzEo1
- LINE Messenger >> http://adf.ly/ItTfN
- LUCKY Patcher >> http://adf.ly/ItTlN
- MAGIC LOCKER >> http://adf.ly/IzF5s
- Market Enable >> http://adf.ly/ItTqu
- Minilyrics (Player + Lirik) >> http://adf.ly/ItTwV
- MIVO TV (TV Online) >> http://adf.ly/ItU3X
- MOBO Launcher >> http://adf.ly/ItUAT
- MY QUR'AN INA >> http://adf.ly/ItUFo
- Network signal speed boost (buatygbermasalah dg sinyal internet mungkin app inibisamembantu>> http://adf.ly/IzFFm
- NEXT Launcher (launcher palingpopuler :D) >> http://adf.ly/ItUM2
- Ninja Morph (Buat edit2tampilan) >> http://adf.ly/ItUTj
- Nophiette For Android >> http://adf.ly/ItUcM
- Office Calculator >> http://adf.ly/ItUkH
- Office Suite >> http://adf.ly/ItUqR
- Opera Mini NEXT >> http://adf.ly/ItUwx
- Pandora FM Radio >> http://adf.ly/ItV4I
- POWER AMP FULL >> http://adf.ly/IzFTc
- Photo wonder (App edit potoyang keren n simpel) >> http://adf.ly/ItV95
- PICSART (sama kayak atasnyagan) >> http://adf.ly/ItVHu
- Picsay PRO (editorpototerbaikkatanyaaa>> http://adf.ly/ItVPc
- PLAY NOW >> http://adf.ly/IzFcu
- Quick office PRO >> http://adf.ly/ItWbY
- Quick Pic >> http://adf.ly/ItWh0
- RAM Boster PRO >> http://adf.ly/ItWnf
- RelaxeMelodie (cocokbuatninabobok)>> http://adf.ly/ItWwM
- Remote control collection >> http://adf.ly/ItX6c
- Remote Mouse ( buat HH jadiMouse laptop) >> http://adf.ly/ItXCy
- ROBIN (SIRI for android) >> http://adf.ly/ItXII
- ROM Manager Premium >> http://adf.ly/ItXNZ
- RAM Toolbox PRO >> http://adf.ly/ItXVt
- Screen Cast (buatrekamaktifitaslayarHH anda) http://adf.ly/ItXbr
- SET CPU >> http://adf.ly/IzFni
- Root Explorer >> http://adf.ly/ItXli
- SD Maid PRO (buat cleansystem,chace, termasukbersihin thumbnail ygnakal) >> http://adf.ly/ItXxJ
- Sensor music player (mutermusikdengan sensor gan. mantaptinggal shake) >>http://adf.ly/ItYEW
- SKYVI ( SIRI for android) >> http://adf.ly/ItYLY
- Sleep Talk Recorder (buatrekambagaimanasuara ngorok agan2) D >> http://adf.ly/ItYR9
- Smart LAUNCHER PRO (tidakkalahapikdg Next launcher ) >> http://adf.ly/ItYYu
- Smart measure PRO (buatukurmengukur)>> http://adf.ly/ItYfM
- SPEED TEST >> http://adf.ly/IzFwm
- SPB Shel 3d LAUNCHER >> http://adf.ly/ItYl9
- SS LAUNCHER >> http://adf.ly/ItYs3
- SUPER USER ELITE >> http://adf.ly/ItYwQ
- SUPER SU >> http://adf.ly/IzG4G
- SUPER SU PRO >> http://adf.ly/IzGDI
- Sygic 3d ( Maps 3d) >> http://adf.ly/ItZ1F
- TAGIHAN LISTRIK >> http://adf.ly/IzGNv
- Tech Calculator >> http://adf.ly/ItZ8F
- TeksStyler Keyboard FULL (BuatketikhurufunicodeBB style) >> http://adf.ly/QCDkm
- Titanium Backup PRO >> http://adf.ly/ItZOE
- Titanium backup >> http://adf.ly/ItZSk
- Track ID (anecomotdariXTipoanegan,tested n work di Galyoung) >> http://adf.ly/ItZWi
- TRANSLATE >> http://adf.ly/IzGaY
- TTPod Music Player (patutdicobagan)>> http://adf.ly/ItZei
- Tube mate (buat downloaddariyoutube) http://adf.ly/ItZlq
- Vignatte camera >> http://adf.ly/Ita8i
- Walkman Black transparant >> http://adf.ly/ItaDP
- Walkman rainbow >> http://adf.ly/IzBPV
- Ways reward locker (Lockscreen)>> http://adf.ly/ItaLk
- Whatsapp Custom BBM Style (BBMfor android) >> http://adf.ly/ItaV1
- Whatsapp Custom BBM Style (BBMfor android) UPDATE >>http://adf.ly/JWTMj
- Whatsapp PLUS New >> http://adf.ly/Itacu
- Whatsapp plus Theme >> http://adf.ly/Iz8zh
- Wifi file transfer (buat parawifiers) >> http://adf.ly/ItaiM
- Wifi Protector (antisisapiituperlugan:D) >> http://adf.ly/ItanI
- Wifi Chat >> http://adf.ly/ItatR
- Winamp PRO >> http://adf.ly/ItaxD
- Windows Phone magic locker >> http://adf.ly/Itb0b
- XDA PREMIUM >> http://adf.ly/IzNaF
- XPERIA T Launcher >> http://adf.ly/Itb4t
- ZEDGE (market) >> http://adf.ly/ItbA4
- Zello (walky talky) >> http://adf.ly/ItbDu
Jumat, 22 November 2013
Rabu, 13 November 2013
MULTIPLEX dan DEMULTIPLEX
Multiplexing ialah Teknik menggabungkan beberapa
sinyal atau informasi untuk dikirimkan secara bersamaan dan menjadi satu
saluran saja. Dimana perangkat yang melakukan Multiplexing disebut Multiplexer
atau disebut juga dengan istilah Transceiver / Mux. Dan untuk di sisi penerima,
gabungan sinyal – sinyal itu akan kembali di pisahkan sesuai dengan tujuan
masing - masing. Proses ini disebut dengan Demultiplexing
Multiplexing memiliki Tujuan utama yaitu untuk
menghemat jumlah saluran fisik misalnya kabel, pemancar & penerima
(transceiver), atau kabel optik. Contoh aplikasi dari teknik multiplexing ini
adalah pada jaringan transmisi jarak jauh, baik yang menggunakan kabel maupun
yang menggunakan media udara (wireless atau radio). Sebagai contoh, satu helai
kabel optik Surabaya-Jakarta bisa dipakai untuk menyalurkan ribuan percakapan
telepon. Idenya adalah bagaimana menggabungkan ribuan informasi percakapan
(voice) yang berasal dari ribuan pelanggan telepon tanpa saling bercampur satu
sama lain.Contoh lainya ialah dalam dunia elektronik, multipleksing mengijinkan
beberapa sinyal analog untuk diproses oleh satu analog ke digital converter
(ADC), dan dalam telekomunikasi, beberapa panggilan telepon dapat disalurkan
menggunakan satu kabel.Anda bisa membayangkan bukan jika diatas langit atau di
atas rumah kita banyak kabel-kabel yang berhubungan ? J
Terdapat sebuah alat untuk melakukan multiplexing
dan demultiplexing,nama alat tersebut untuk
melakukan multiplexing disebut multiplekser (MUX) dan alat yang
melakukan proses yang berlawanan disebut demultiplekser, (DEMUX).

Beberapa alasan penggunan multiplex:
- Menghemat
biaya penggunaan saluran komunikasi
-
Memanfaatkan sumber daya seefisien mungkin
- Kapasitas
terbatas dari saluran telekomunikasi digunakan semaksimum mungkin
-
Karakteristik permintaan komunikasi pada umumnya memerlukan penyaluran
data dari beberapa terminal ke titik
yang sama
Terdapat beberapa teknik untuk melakukan multiplxing
:
1.
Frequency Division Multiplexing (FDM)
·
Menggabungkan beberapa sinyal dengan masing-masing frequency.yaitu
dengan cara menata tiap informasi sedemikian rupa sehingga menempati satu
alokasi frekuensi selebar 4 khz.

Kelebihan dan kekurangan
Kelebihan:
• FDM tidak sensitif terhadap perambatan
/perkembangan keterlambatan. Tehnik persamaan saluran (channel equalization)
yang diperlukan untuk sistem FDM tidak sekompleks seperti yang digunakan pada
sistem TDM.
Kekurangan:
• Adanya kebutuhan untuk memfilter bandpass, yang
harganya relatif mahal dan rumit untuk dibangun (penggunaan filter tersebut
biasanya digunakan dalam transmitter dan receiver)
• Penguat tenaga (power amplifier) di transmitter
yang digunakan memiliki karakteristik nonlinear (penguat linear lebih komplek
untuk dibuat), dan amplifikasi nonlinear mengarah kepada pembuatan komponen
spektral out-of-band yang dapat mengganggu saluran FDM yang lain.
2. Time Divison Multiplexing (
TDM )
· Menggabungkan beberapa sinyal atau informasi
dengan membagi masing-masing waktu untuk saluran yang sama.
Contoh di telekomunikasi :
Teknik ini dinamakan Time Division Multiplexing
(TDM) dimana tiap pelanggan diberi jatah waktu (time slot) tertentu sedemikian
rupa sehingga semua informasi percakapan bisa dikirim melalui satu saluran
secara bersama-sama tanpa disadari oleh pelanggan bahwa mereka sebenarnya
bergantian menggunakan saluran. Kenapa si pelanggan tidak merasakan pergantian
itu? Karena pergantiannya terjadi setiap 125 microsecond; berapapun jumlah
pelanggan atau informasi yang ingin di-multiplex, setiap pelanggan akan
mendapatkan giliran setiap 125 microsecond, hanya jatah waktunya semakin cepat.
Prinsip TDM adalah menerapkan prinsip penggiliran waktu
pemakaian saluran transmisi dengan mengalokasikan satu slot waktu (time slot ) bagi setiap pemakai saluran
(user).
TDM biasanya digunakan untuk komunikasi point to
point. Pada TDM, penambahan peralatan pengiriman data lebih mudah dilakukan.
TDM lebih efisien daripada FDM.
cara kerja block diagram TDM :

Dari gambar diatas dapat dilihat dari cara kerja
TDM, dimana input dari masing-masing chanel atau informasi melewati swith yang
bekerja secara bersamaan pada swith atau kontak yang ada pada demultiplexer.Jadi
setiap chanel atau informasi dapat melewati swith dengan atau sesuai waktu yang
ditentukan. Lalu masuk ke demultiplexer dan melewati sebuah filter / penyaring
sebelum menjadi chanel atau informasi sebelumnya.
3 Code
Division Multiplexing (CDM)
Code Division Multiplexing (CDM) dirancang untuk
menanggulangi kelemahan-kelemahan yang dimiliki oleh teknik multiplexing
sebelumnya, yakni TDM dan FDM. CDM (Code Division Multiplexing), biasa dikenal
sebagai Code Division Multiple Access (CDMA), merupakan sebuah bentuk
pemultipleksan (bukan sebuah skema pemodulasian) dan sebuah metode akses secara
bersama yang membagi kanal tidak berdasarkan waktu (seperti pada TDMA) atau
frekuensi (seperti pada FDMA), namun dengan cara mengkodekan data dengan sebuah
kode khusus yang diasosiasikan dengan tiap kanal yang ada dan mengunakan
sifat-sifat interferensi konstruktif dari kode-kode khusus itu untuk melakukan
pemultipleksan. Singkatnya, CDM dapat melewatkan beberapa sinyal dalam waktu
dan frekuensi yang sama. Tiap kanal dibedakan berdasarkan kode-kode pada
wilayah waktu dan frekuensi yang sama.
Contoh aplikasinya pada saat ini adalah jaringan
komunikasi seluler CDMA (Flexi).
Block Code Division Multiplexing (CDM) atau gambaran
system komunikasi menggunakan CDM
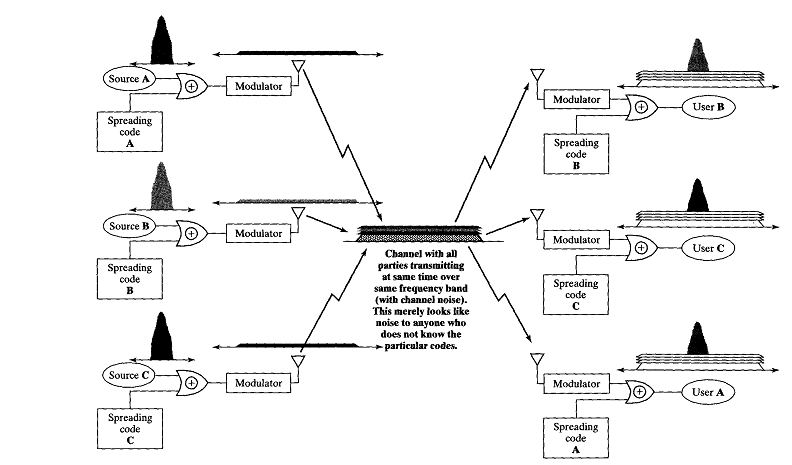
Prinsip kerja dari CDM adalah sebagai berikut :
1. Kepada
setiap entitas pengguna diberikan suatu kode unik (dengan panjang 64 bit)
yangdisebut chip spreading code.2
2. Untuk
pengiriman bit ‘1’, digunakan representasi kode (chip spreading code) tersebut.
3.
Sedangkan untuk pengiriman bit ‘0’, yang digunakan adalah inverse dari
kode tersebut.
4. Pada
saluran transmisi, kode-kode unik yang dikirim oleh sejumlah pengguna akan
ditransmisikan dalam bentuk hasil penjumlahan (sum) dari kode-kode tersebut.
5. Di sisi penerima, sinyal hasil
penjumlahan kode-kode tersebut akan dikalikan dengan kode unik dari si pengirim
(chip spreading code) untuk diinterpretasikan.
PENDAHULUAN
Kompresi Data merupakan cabang ilmu komputer yang
bersumber dari Teori Informasi. Teori Informasi sendiri adalah salah satu
cabang Matematika yang berkembang sekitar akhir dekade 1940-an. Tokoh utama
dari Teori Informasi adalah Claude Shannon dari Bell Laboratory.
Teori Informasi mengfokuskan pada berbagai metode
tentang informasi termasuk penyimpanan dan pemrosesan pesan. Teori Informasi
mempelajari pula tentang redundancy (informasi tak berguna) pada pesan. Semakin
banyak redundancy semakin besar pula ukurang pesan, upaya mengurangi redundancy
inilah yang akhirnya melahirkan subyek ilmu tentang Kompresi Data.
Teori Informasi menggunakan terminologi entropy
sebagai pengukur berapa banyak informasi yang dapat diambil dari sebuah pesan.
Kata “entropy” berasal dari ilmu termodinamika. Semakin tinggi entropy dari
sebuah pesan semakin banyak informasi yang terdapat di dalamnya. Entropy dari
sebuah simbol didefinisikan sebagai nilai logaritma negatif dari probabilitas
kemunculannya. Untuk menentukan konten informasi dari sebuah pesan dalam jumlah
bit dapat digunakan rumus sebagai berikut:
number of bits = -log base 2 (probability)
Entropy dari keseluruhan pesan adalah jumlah dari
keseluruhan entropy dari seluruh symbol.
PENGERTIAN KOMPRESI DATA
- Kompresi
berarti memampatkan / mengecilkan ukuran
- Kompresi
data adalah proses mengkodekan informasi menggunakan bit atau
information-bearing unit yang lain yang lebih rendah daripada representasi
data yang tidak terkodekan dengan suatu sistem enkoding tertentu.
- Contoh
kompresi sederhana yang biasa kita lakukan misalnya adalah menyingkat
kata-kata yang sering digunakan tapi sudah memiliki konvensi umum.
Misalnya: kata “yang” dikompres menjadi kata “yg”
- Pengiriman
data hasil kompresi dapat dilakukan jika pihak pengirim/yang melakukan
kompresi dan pihak penerima memiliki aturan yang sama dalam hal kompresi
data
- Pihak
pengirim harus menggunakan algoritma kompresi data yang sudah baku dan
pihak penerima juga menggunakan teknik dekompresi data yang sama dengan
pengirim sehingga data yang diterima dapat dibaca / di-dekode kembali
dengan benar
- Kompresi
data menjadi sangat penting karena memperkecil kebutuhan penyimpanan data,
mempercepat pengiriman data, memperkecil kebutuhan bandwidth
- Teknik
kompresi bisa dilakukan terhadap data teks/biner, gambar (JPEG, PNG,
TIFF), audio (MP3, AAC, RMA, WMA), dan video (MPEG, H261, H263)
Jenis Kompresi Data
Berdasar mode penerimaan data yang
diterima manusia :
- Dialoque
Mode: yaitu proses penerimaan data dimana pengirim dan penerima seakan
berdialog (real time), seperti pada contoh video conference. Dimana
kompresi data harus berada dalam batas penglihatan dan pendengaran
manusia. Waktu tunda (delay) tidak boleh lebih dari 150 ms, dimana
50 ms untuk proses kompresi dan dekompresi, 100 ms mentransmisikan data
dalam jaringan
- Retrieval
Mode: yaitu proses penerimaan data tidak dilakukan
secara real time
Dapat dilakukan fast
forward dan fast rewind di client
Dapat dilakukan random access terhadap data dan
dapat bersifat interaktif
Kompresi Data Berdasarkan Output :
- Lossy
Compression
Teknik kompresi dimana data hasil dekompresi tidak
sama dengan data sebelum kompresi namun sudah “cukup” untuk
digunakan. Contoh: Mp3, streaming media, JPEG, MPEG, dan WMA.
Kelebihan: ukuran file lebih kecil dibanding
loseless namun masih tetap memenuhi syarat untuk digunakan.
Biasanya teknik ini membuang bagian-bagian data yang
sebenarnya tidak begitu berguna, tidak begitu dirasakan, tidak begitu dilihat
oleh manusia sehingga manusia masih beranggapan bahwa data tersebut masih bisa
digunakan walaupun sudah dikompresi.
Misal terdapat image asli berukuran 12,249
bytes, kemudian dilakukan kompresi dengan JPEG kualitas 30 dan berukuran 1,869
bytes berarti image tersebut 85% lebih kecil dan ratio kompresi 15%
- Loseless
Teknik kompresi dimana data hasil kompresi dapat
didekompres lagi dan hasilnya tepat sama seperti data sebelum proses
kompresi. Contoh aplikasi: ZIP, RAR, GZIP, 7-Zip
Teknik ini digunakan jika dibutuhkan data setelah
dikompresi harus dapat diekstrak/dekompres lagi tepat sama. Contoh pada
data teks, data program/biner, beberapa image seperti GIF dan PNG
Kadangkala ada data-data yang setelah dikompresi
dengan teknik ini ukurannya menjadi lebih besar atau sama
Berdasarkan tipe peta kode yang digunakan untuk
mengubah pesan awal (isi file input) menjadi sekumpulan codeword,
metode kompresi terbagi menjadi dua kelompok, yaitu :
(a) Metode statik :
menggunakan peta kode yang selalu sama. Metode
ini membutuhkan dua fase (two-pass): fase pertama untuk menghitung
probabilitas kemunculan tiap simbol/karakter dan menentukan peta kodenya, dan
fase kedua untuk mengubah pesan menjadi kumpulan kode yang akan ditransmisikan.
Contoh: algoritma Huffman statik.
(b) Metode dinamik (adaptif) :
menggunakan peta kode yang dapat berubah dari waktu
ke waktu. Metode ini disebut adaptif karena peta kode mampu beradaptasi
terhadap perubahan karakteristik isi file selama proses kompresi berlangsung.
Metode ini bersifat onepass, karena hanya diperlukan satu kali
pembacaan terhadap isi file. Contoh: algoritma LZW dan DMC.
Klasifikasi Teknik Kompresi
- Entropy
Encoding
Bersifat loseless
Tekniknya tidak
berdasarkan media dengan spesifikasi dan karakteristik tertentu namun
berdasarkan urutan data.
Statistical encoding, tidak memperhatikan semantik
data.
Mis: Run-length coding, Huffman coding, Arithmetic
coding
- Source
Coding
Bersifat lossy
Berkaitan dengan data semantik (arti data) dan
media.
Mis: Prediction (DPCM, DM), Transformation (FFT,
DCT), Layered Coding (Bit position, subsampling, sub-band coding), Vector
quantization
- Hybrid
Coding
Gabungan antara lossy + loseless
mis: JPEG, MPEG, H.261, DVI
Secara umum kompresi data terdiri dari dua kegiatan
besar, yaitu Modeling dan Coding. Proses dasar dari kompresi data adalah
menentukan serangkaian bagian dari data (stream of symbols) mengubahnya menjadi
kode (stream of codes). Jika proses kompresi efektif maka hasil dari stream of
codes akan lebih kecil dari segi ukuran daripada stream of symbols. Keputusan
untuk mengindentikan symbols tertentu dengan codes tertentu adalah inti dari
proses modeling. Secara umum dapat diartikan bahwa sebuah model adalah kumpulan
data dan aturan yang menentukan pasangan antara symbol sebagai input dan code
sebagai output dari proses kompresi. Sedangkan coding adalah proses untuk
menerapkan modeling tersebut menjadi sebuah proses kompresi data.
I.Coding
Melakukan proses encoding dengan menggunakan ASCII
atau EBDIC yang merupakan standar dalam proses komputasi memberikan kelemahan
mendasar apabila dilihat dari paradigma kompresi data. ASCII dan EBDIC
menggunakan jumlah bit yang sama untuk setiap karakter, hal ini menyebabkan
banyak bit yang ”terbuang” untuk merepresentasikan karakter-karakter yang
sebenarnya jarang muncul pada sebuah pesan.
Salah satu cara mengatasi permasalahan di atas
adalah dengan menggunakan Huffman-coding. Huffman-coding yang dikembangkan oleh
D.A. Huffman mampu menekan jumlah redundancy yang terjadi pada sebuah pesan
yang panjangnya tetap. Huffman-coding bukanlah teknik yang paling optimal untuk
mengurangi redundancy tetapi Huffman-coding merupakan teknik terbaik untuk
melakukan coding terhadap symbol pada pesan yang panjangnya tetap. Permasalahan
utama dengan Huffman-coding adalah hanya bisa menggunakan bilangan bulat untuk
jumlah bit dari setiap code. Jika entropy dari karakter tersebut adalah 2,5
maka apabila melakukan pengkodean dengan Huffman-coding karakter tersebut harus
terdiri dari 2 atau 3 bit. Hal tersebut membuat Huffman-coding tidak bisa
menjadi algoritma paling optimal dalam mengatasi redundancy ini.
Huffman-coding memang kurang efisien karena untuk
melakukan pengkodean kita harus menggunakan bilangan bulat. Walaupun demikian
Huffman-coding sangat mudah digunakan dan sampai awal era 90-an di mana
prosesor komputer masih sulit untuk melakukan komputasi bilangan pecahan
Huffman-coding dianggap paling rasional untuk diaplikasikan pada proses
kompresi data. Setelah kelahiran prosesor yang mampu melakukan operasi bilangan
pecahan dengan cepat maka banyak algoritma coding baru bermunculan dan salah
satunya adalah Arithmatic-coding.
Arithmatic coding lebih kompleks dan rumit
dibandingkan Huffman-coding, tetapi di sisi lain Arithmatic-coding memberikan
optimalisasi yang lebih tinggi. Arithmatic-coding memungkinkan jumlah bit dalam
pecahan karena arithmatic coding tidak bekerja per karakter dari pesan tetapi
langsung pada keseluruhan pesan. Misalnya entropy dari karakter e pada pesan
adalah 1,5 bit maka pada output code pun jumlah bit-nya adalah 1,5 dan bukan 1
atau 2 seperti pada Huffman-coding.
ALGORITMA KOMPRESI DATA
Algoritma Shannon-Fano dan Algortima Huffman.
Walaupun saat ini sudah bukan lagi proses coding yang menghasilkan kompresi
paling optimal namun algoritma Shannon-Fano dan Algoritma Huffman adalah dua
algoritma dasar yang sebaiknya dipahami oleh mereka yang mempelajari tentang
kompresi data.
1.
Algoritma Shannon-Fano
Teknik coding ini dikembangkan oleh dua orang dalam
dua buah proses yang berbeda, yaitu Claude Shannon di Bell Laboratory dan R.M.
Fano di MIT, namun karena memiliki kemiripan maka akhirnya teknik ini dinamai
dengan mengggabungkan nama keduanya. Pada dasarnya proses coding dengan
algoritma ini membutuhkan data akan frekuensi jumlah kemunculan suatu karakter
pada sebuah pesan. Tiga prinsip utama yang mendasari algoritma ini adalah:
a. Simbol yang berbeda memiliki kode yang
berbeda
b. Kode untuk symbol yang sering muncul memiliki
jumlah bit yang lebih sedikit dan sebaliknya symbol yang jarang muncul
memiliki kode dengan jumlah bit lebih besar.
c. Walaupun berbeda jumlah bit-nya tetapi kode harus
tetap dikodekan secara pasti (tidak ambigu).
Berikut adalah langka-langkah Algoritma Shannon-Fano
:
1. Buatlah tabel yang memuat frekuensi kemunculan
dari tiap karakter.
2. Urutkan berdasar frekuensi tersebut dengan
karakter yang frekuensinya paling sering muncul berada di atas dari daftar
(descending).
3. Bagilah 2 tabel tersebut dengan jumlah total
frekuensi pada bagian atas mendekati jumlah total frekuensi pada bagian bawah
(lihat tabel 3).
4. Untuk bagian paro atas berikan kode 0 dan pada
paro bawah berikan kode
5. Ulangi langkah 3 dan 4 pada masing-masing paro
tadi hingga seluruh symbol selesai dikodekan.
2.
Algoritma Huffman
Algoritma Huffman memiliki kemiripan karakteristik
dengan Algoritma Shannon-Fano. Masing-masing simbol dikodekan dengan deretan
bit secara unik dan simbol yang paling sering muncul mendapatkan jumlah bit
yang paling pendek. Perbedaan dengan Shannon-Fano adalah pada proses
pengkodean. Jika algoritma Shannon-Fano membangun tree dengan pendekatan
top-down, yaitu dengan memberikan bit pada tiap-tiap simbol dan melakukannya
secara berurutan hingga seluruh leaf mendapatkan kode bit masing-masing.
Sedangkan algoritma Huffman sebaliknyamemberikan kode mulai dari leaf secara
berurutan hingga mencapai root.
Prosedur untuk membangun tree ini sederhana dan
mudah dipahami. Masing-masing simbol diurutkan sesuai frekuensinya, frekuensi
ini dianggap sebagai bobot dari tiap simbol, dan kemudian diikuti dengan
langkah-langkah sebagai berikut:
1. Dua node bebas dengan bobot terendah dipasangkan.
2. Parent node untuk kedua node pada langkah
sebelumnya dibuat. Jumlahkan frekuensi keduanya dan gunakan sebagai bobot.
3. Sekarang parent node berperan sebagai node bebas.
4. Berikan kode 0 untuk node kiri dan 1 untuk node
kanan.
5. Ulangi langkah di atas sampai hanya tersisa satu
node. Sisa satu node inilah yang disebut sebagai root.
II. Modeling
Jika coding adalah roda dari sebuah mobil maka
modeling adalah mesinnya. Sebaik apapun algoritma untuk melakukan coding tanpa
model yang baik kompresi data tidak akan pernah terwujud. Kompresi Data
Lossless pada umumnya diimplementasikan menggunakan salah satu dari dua tipe
modeling, yaitu statistical atau dictionary-based. Statistical-modeling
melakukan prosesnya menggunakan probabilitas kemunculan dari sebuah symbol
sedangkan dictionary-based menggunakan kode-kode untuk menggantikan sekumpulan
symbol.
1. Statistical Modeling
Pada bentuk paling sederhananya,
statistical-modeling menggunakan tabel statis yang berisi probabilitas
kemunculan suatu karakter atau symbol. Tabel ini pada awalnya bersifat
universal, sebagai contoh pada bahasa Inggris karakter yang paling sering
muncul adalah huruf “e” maka karakter ini memiliki 9 probabilitas tertinggi
pada file teks yang berbahasa Inggris.
Menggunakan tabel universal pada akhirnya tidak
memuaskan para ahli kopresi data karena apabila terjadi perubahan pada subyek yang
dikompresi dan tidak sesuai dengan tabel universal maka akan terjadi penurunan
rasio kompresi secara signifikan. Akhirnya muncul modeling dengan menggunakan
tabel yang adaptif, di mana tabel tidak lagi bersifat statis tetapi bisa
berubah sesuai dengan kode. Pada prinsipnya dengan model ini, sistem melakukan
penghitungan atau scan pada keseluruhan data setelah itu barulah membangun
tabel probabilitas kemunculan dari tiap karakter atau symbol.
Model ini kemudian dikembangkan lagi menjadi
adaptive statistical modeling di mana sistem tidak perlu melakukan scan ke
seluruh symbol untuk membangun tabel statistik, tetapi secara adaptif melakukan
perubahan tabel pada proses scan karakter per karakter.
2. Dictionary Based Modeling
Jika statistical model pada umumnya melakukan proses
encode simbol satu per satu mengikuti siklus: baca karakter à
hitung probabilitas à buat kodenya maka dictionary-based
modeling menggunakan mekanisme yang berbeda. Dictionary-based modeling membaca
input data dan membandingkannya dengan isi dictionary. Jika sekumpulan string
sesuai dengan isi dictionary maka indeks dari dictionary entry lah yang
dikeluarkan sebagai output dan bukan kodenya. Sebagai perumpamaan dari
dictionary-based dapat digunakan makalah ilmiah sebagai contoh. Saat kita
membaca makalah ilmiah kita sering membaca nomor-nomor referensi yang bisa kita
cocokkan dengan daftar pustaka di belakang. Hal ini mirip dengan proses pada
dictionary-based modeling.
PERBANDINGAN ALGORITMA PADA KOMPRESI
DATA
|
Symbol
|
Jumlah
|
Kode
Shannon
Fano
|
Kode
Huffman
|
Ukuran
Shannon-
Fano
|
Jumlah
Bit
Shannon-
Fano
|
Ukuran
Hufman
|
Jumlah
Bit
Huffman
|
|
A
|
15
|
00
|
0
|
2
|
30
|
1
|
15
|
|
B
|
7
|
01
|
100
|
2
|
14
|
3
|
21
|
|
C
|
6
|
10
|
101
|
2
|
12
|
3
|
18
|
|
D
|
6
|
110
|
110
|
3
|
18
|
3
|
18
|
|
E
|
5
|
111
|
111
|
3
|
15
|
3
|
15
|
|
TOTAL BIT
|
89
|
87
|
|||||
KESIMPULAN
Berdasarkan penjelasan di atas, kita dapat
menyimpulkan bahwa Kompresi Data dapat mempermudahkan dalam hal penyimpanan
file yang begitu besar. Dan media penyimpanan kita bisa menampung data
sebanyak- banyaknya.
REFERENSI
Nelson, M., Gailly, J.L., The Data Compression Book,
Second Edition. M&T Books, New
York, 1996
www.google.com
Langganan:
Postingan (Atom)
